Broomlib. Librería de procesado para Machine Learning
2 minutos de lecturaRepositorio GitHub: https://github.com/GonzaloPerez1/broomlib
Repositorio GitHub Fork: https://github.com/casiopa/broomlib.git
Pypi: https://pypi.org/project/broomlib/
¿Tienes un deadline de Machine Learning imposible de cumplir? Esta línea de código puede ayudarte:
pip install broomlib
Broomlib es un paquete de Python que busca facilitar el preprocesado de datos antes de la aplicación de modelos de Machine Learning. La librería abarca tres áreas:
- Visualización inicial del dataset
- Limpieza de datos
- Preprocesado de los datos mediante Machine learning
Como colaboradora de esta librería, principalmente para el módulo de visualización, me gustaría destacar algunas funciones que pueden ser muy útiles antes de aplicar un modelo de Machine Learning sobre todo si el tiempo apremia.
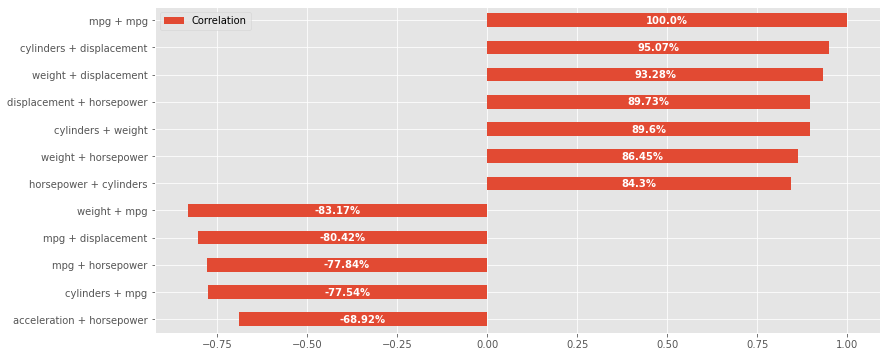
corr_bars
Muestra un gráfico de barras horizontales de las variables más correlacionadas entre sí, de pares a pares. Presents a Pandas horizontal bar plot of the most correlated feature pairs and their correlation coefficient. Esta función solo utiliza variables númericas.
En todas las gráficas del módulo de visualización de broomlib hay dos parámetros comunes:
figsize: determina el tamaño y proporción de la imagen.style: estilo de gráfico matplotlib. Para buscar los estilos disponibles puede usarse:plt.style.available.
Código de ejemplo:
from broomlib import visualization as vis
import seaborn as sns
mpg = sns.load_dataset('mpg')
vis.corr_bars(mpg, threshold=0.6, figsize=(13, 6))
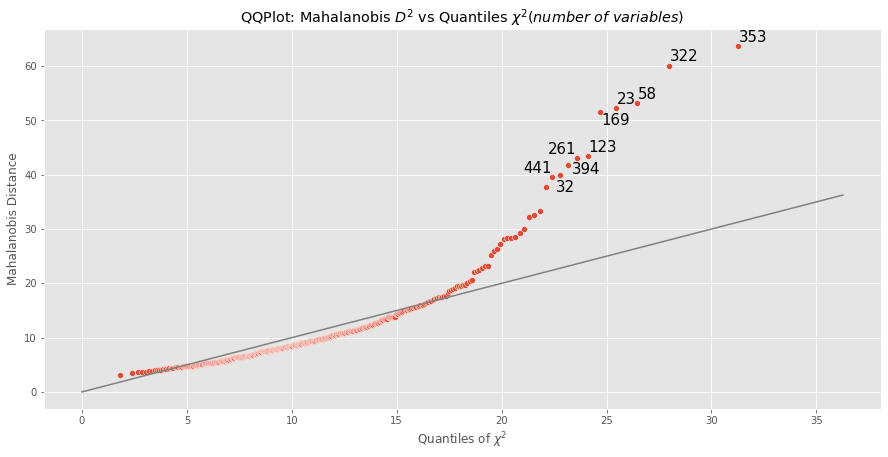
outliers_mahalanobis_plot
Este gráfico muestra los outliers del dataset. Para determinarlos utiliza la distancia de Mahalanobis para comparar cada punto con la distribución Chi Square. Los puntos más extremos son los que llevan los índices y su número se determina mediante el parámetro extreme_points. Esta función solo utiliza variables númericas.
Código de ejemplo:
from broomlib import visualization as vis
from sklearn import datasets
import pandas as pd
diabetes = datasets.load_diabetes()
df = pd.DataFrame(diabetes.data)
vis.outliers_mahalanobis_plot(df, extreme_points=10, figsize=(15,7), style='ggplot')
broomResample
El objetivo de broomResample es afrontar el no poco frecuente problema de tener un target desbalanceado. Una posible solución sería hacer un oversampling de la clase minoritaria, muchas veces un duplicado de registros que no aporta información al modelo.
Para la función aplica una mezcla de técnicas. En primer lugar hace un undersampling de la clase mayoritaria que puede ser personalizado mediante el párametro sampling_strategy_o. Después, se aplica un oversampling mediante la técnica SMOTE Synthetic Minority Oversampling Technique que también puede ser parametrizada mediante el argumento sampling_strategy_o.
Código de ejemplo:
from broomlib import broomResample
from collections import Counter
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
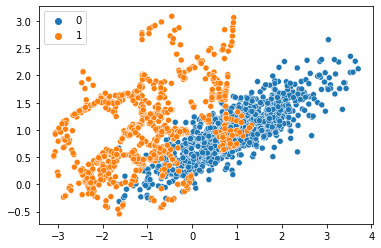
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
print('Original dataset:', Counter(y))
sns.scatterplot(X.T[0], X.T[1], hue=y)
plt.show()
X_resampled, y_resampled = broomResample(X,y)
print('Resampled dataset samples per class:', Counter(y_resampled))
sns.scatterplot(X_resampled.T[0], X_resampled.T[1], hue=y_resampled)
plt.show()
Original dataset: Counter({0: 9900, 1: 100})
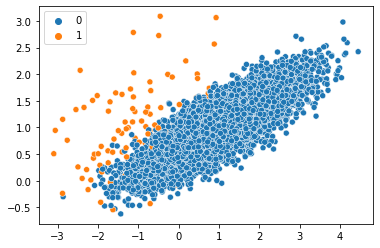
Resampled dataset samples per class Counter({0: 990, 1: 990})